1.3.1 SQL이 느린 이유
SQL이 느린이유?
- 디스크 I/O 때문!
- I/O = 잠
- OS가 I/O를 처리하는 동안 프로세스는 잠을 잔다!
- 디스크에서 데이터를 읽어야 할 때는 CPU를 OS에 반환하고 잠시 수면 상태에서 I/O가 완료되기를 대기 (I/O Call 하고 CPU 반환 -> SLEEP)
1.3.2 DB 저장구조
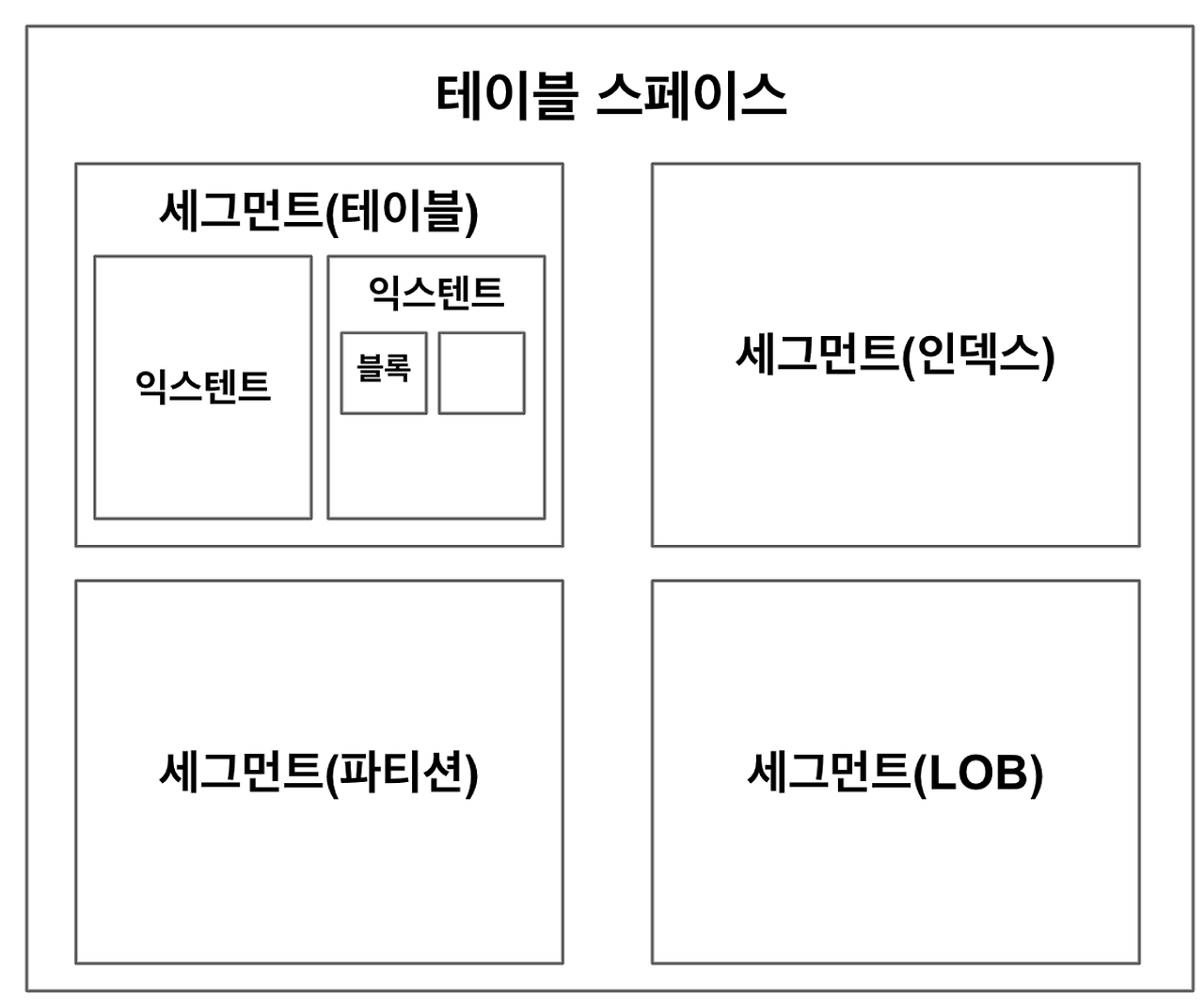
데이터를 저장하려면 가장 먼저 테이블 스페이스 가 필요하다
- 테이블 스페이스 : 세그먼트를 담는 컨테이너 (여러 개의 데이터 파일로 구성)
- 세그먼트 : 테이블, 인덱스 처럼 데이터 저장 공간이 필요한 오브젝트 (여러 익스텐트로 구성)
- 익스텐트 : 공간을 확장하는 단위 (연속된 블록의 집합)
- 블록(페이지) : 레코드를 실제로 저장하는 공간
한 블록은 하나의 테이블이 독점 (한 블록에 저장된 레코드는 모두 같은 테이블 레코드)
한 익스텐트도 하나의 테이블이 독점
하나의 테이블 스페이스를 여러 데이터 파일로 구성 => 파일 경합을 줄이기 위해 dbms가 데이터를 가능한 여러 데이터 파일로 분산 저장
<요약>
| 블록(페이지) | 데이터를 읽고 쓰는 단위 |
| 익스텐트 | 공간을 확장하는 단위, 연속된 블록 집합 |
| 세그먼트 | 데이터 저장공간이 필요한 오브젝트 (테이블, 인덱스, 파티션, LOB 등) |
| 테이블스페이스 | 세그먼트를 담는 콘테이너 |
| 데이터파일 | 디스크 상의 물리적인 OS 파일 |
1.3.4 시퀀셜 액세스vs 랜덤 액세스
테이블 또는 인덱스 블록을 읽는 방식 : 시퀀셜 / 랜덤
(1) 시퀀셜
- 논리적 or 물리적으로 연결된 순서에 따라 차례대로 블록을 읽는 방식
- FULL TABLE SCAN :
- 익스텐트 맵은 각 익스텐트의 첫 번째 블록 주소 값을 가짐
- 읽어야 할 익스텐트 목록을 익스텐트 맵에서 얻고, 각 익스텐트의 첫 번째 블록 뒤에 연속해서 저장된 블록을 순서대로 읽는 방식
(2) 랜덤
- 논리적, 물리적 순서를 따르지 않고, 레코드 하나를 읽기 위해 한 블록씩 접근
1.3.5 논리적 I/O vs 물리적 I/O
DB 버퍼 캐시 (데이터 캐시) : 디스크에서 어렵게 읽은 데이터 블록을 캐싱해 둠으로써 같은 블록에 대한 반복적인 I/O 콜을 줄임
라이브러리 캐시 : SQL과 실행계획, DB 저장형 함수/프로시저 등을 캐싱하는 "코드 캐시" (sql 파싱과 관련 있었음!)
만약, 서버 프로세스와 데이터파일 사이에 있는 캐시에서 블록(페이지)를 찾는다면 이득 (프로세스가 잠을 안자도 되므로)
논리적 블록 IO : 메모리 버퍼캐시에서 발생한 총 블록 I/O를 의미
물리적 블록 IO : 디스크에서 발생한 총 블록 I/O를 의미
SQL 처리 도중 읽어야할 블록을 캐시에서 찾지 못했을 경우 디스크로 접근 (= 논리적 블록 I/O 중 일부를 물리적으로 I/O)
버퍼캐시히트율 (BCHR) : BCHR이 높다고 효율적인 SQL은 아님 (같은 블록을 비효율적으로 반복해서 읽으면 BCHR 향상)
물리적 I/O = 논리적 I/O x (100-BCHR)
논리적 I/O를 줄이면 물리적 I/O도 감소한다. (물리적 I/O 감소는 성능 향상)
논리적 I/O는 통제 가능
물리적 I/O는 직접 줄일 방법 없음 (메모리 증설하여 db버퍼캐시 크기를 늘리는 방법정도)
1.3.6 Single Block IO vs Multiblock IO
캐시에서 찾지 못한 데이터 블록은 I/O call 을 통해 디스크에서 DB 버퍼캐시로 적재하고 읽는다.
Single Block IO
- 한번에 한블록씩 요청해서 메모리에 적재
- 인덱스와 테이블 블록 모두 Single Block IO 방식 (소량 데이터 검색)
Multio BlockIO
- 한번에 여러블록 요청해서 메모리에 적재
- 테이블 전체 스캔할 때, 테이블이 클 때 MultiBlock IO 방식
"읽고자 하는 블록을 db버퍼 캐시에서 찾지 못하면 해당 블록을 디스크에서 읽기 위해 IO Call "
그 동안 프로세스는 대기 큐에서 잠을 잔다.
기왕 잠을 자려면 한꺼번에 많은 양을 요청해야 잠자는 횟수를 줄이고 성능을 높일 수 있다.
(대용량 Full Scan할 때, MultiBlock IO 단위를 크게하면 성능 좋아짐.)
1.3.7 Table Full Scan vs Index Range Scan
(1) Table Full Scan
- Sequential Access
- Multiblock I/O
- 대량 데이터 검색 시 유리
(2) Index Range Scan
- Random Access
- Singleblock I/O
- 소량 데이터 검색 시 유리
- 인덱스에서 "일정량"을 스캔하면서 얻은 ROWID 로 테이블 레코드를 찾아가능 방식 (ROWID : 테이블레코드가 디스크 상에 어디 저장됐는지를 가리키는 위치 정보)
1.3.8 버퍼 캐시 탐색 방법
- 해시함수를 사용해서 나온 결과로 링크드 리스트 헤더를 찾음
- 찾으려고 하는 블록이 나올 때까지 리스트 탐색
- 발견하면 끝
- 없다면 디스크로부터 읽어서 리스트에 추가
- 버퍼는 동시에 사용할 수 없어 락이 필요해서 Latch라는 방식으로 각각의 링크드 리스트마다 락을 걸음
- 버퍼 캐시를 탐색하는 것도 락에 의해서 느릴 수 있으므로, 버퍼 캐시조차 접근하는 것을 줄여야 한다. 즉, 논리적 I/O를 줄여야 한다.
Table Full Scan이 항상 성능 저하를 일으키는 것이 절대 아니다! (대량 데이터 검색시에는 더 유리하므로, 인덱스를 맹신하지 말라!)친절한 SQL 튜닝

출처 : 친절한 SQL 튜닝(저자: 조시형)
'Database > 친절한 SQL 튜닝' 카테고리의 다른 글
| [친절한 SQL 튜닝 스터디] 4장 (0) | 2024.03.28 |
|---|---|
| [친절한 SQL 튜닝 스터디] 3장. 인덱스 튜닝 (0) | 2024.03.27 |
| [친절한 SQL 튜닝 스터디] 2장. 인덱스 기본 (0) | 2024.03.27 |
| [친절한 SQL 튜닝 스터디] 1장. SQL 처리 과정과 I/O - 소프트 파싱, 하드파싱 (0) | 2024.03.26 |
| [친절한 SQL 튜닝 스터디] 1장. SQL 처리 과정과 I/O - 실행계획 (2) | 2024.03.26 |